Postgres vs Mongo
Postgres vs Mongo
❗️ disclaimer ❗️
This story was originally designed for desktop screens. On smaller screens, you’ll see the story content without the charts.intro
As a postgres fanboy I’ve been using it for most of my projects. Yet, there are so many different databases out there. Supposedly some are better for certain use cases than others, but deep down I know it’s a lie and postgres is king. Now that we’ve settled that I’m objective and not biased: let’s dive into the comparison of write and read operations in Mongo and Postgres.
setup
In my lab project I will store mocked user data in Postgres and Mongo. The two most common data operations will be compared: write and read. We know that while Postgres is a relational database, Mongo is a document database. This means that Postgres has a fixed number of columns, while Mongo has a dynamic number of document properties. Mainly. Postgres also offers the JSONB type which is a great way to store unstructured data and this resembles the document model of Mongo.
I’ll aim for a setup which is simple, yet incorporates realtional and document-like characteristics.
Four root level properties in mongo and also four dedicated columns in postgres:
- uuid
- name
- user data (object / JSONB)
The user data is an object with a number of different properties.
In mongo all the properties are stored in the document on the root level and the user data is an object with a different properties.
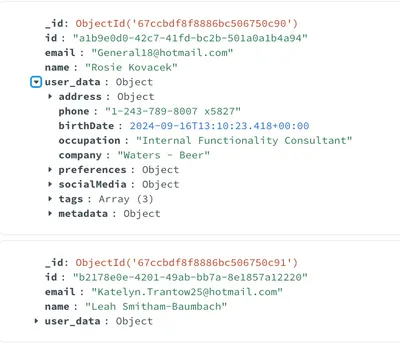
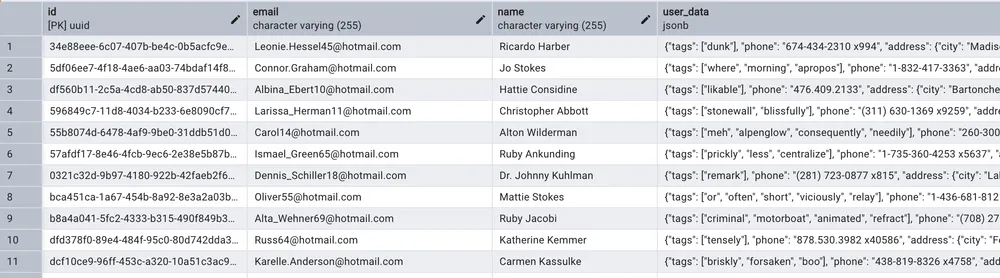
In postgres a fix number of properties are stored in dedicated table columns in atomic form and the user data is stored in the user_data jsonb column with a different properties.
SUMMARY: the the “CR” from CRUD operations were tested in Postgres and Mongo with varying data set sizes. The small set was 1k rows, the medium 100k rows and the large 1M rows. In the first runs no indexes or optimizations were applied. Later on the databases were tuned (partially beyond the line of sane reason, just to squeeze out faster operations and part with “D” from ACID.
Read the story below
CREATE operations
Batch insert 1k records
Postgres is more than four times faster than mongo for 1k records insertion, all at once. Postgres: Average time per record: 0.05ms, Mongo: Average time per record: 0.24ms
Batch insert 100k records
In the second iteration I inserted 100k records in batches of 1k records. Mongo took over the lead.
Average time per record (100k records)
Mongo AVG time per record was 0.0374ms whereas in Postgres 0.0398ms. This means that Mongo manages roughly 26700 records per second whereas Postgres inserts only 25100 records.
Both databases manages a relatively constant speed of around 50ms per batch insertion.
Batch insert 1M records
Batch size is still 1k. In Mongo it took 41.133 seconds for insertion and in postgres 48.057 seconds. Mongo outperforms Postgres by 1,17x. In Mongo AVG time per record is 0.0411ms = 24100 records per second and in Postgres 0.0481ms = 20800 records per second.
to conclude non tuned insertions:
Mongo performed better in most cases. The initial batch takes always a bit longer in Mongo but then it runs at a constant speed which is faster than in Postgres.
In the next part I wanted to test different optimizations which aim for faster insertions both in Postgres and in Mongo.
optimizations in Postgres
Initially I used parameterised queries for the insertions. Then I used the COPY command along with optimized postgres settings. This had some hiccups becasue the pg npm package doesn’t support COPY from stdin
so even though it was supposed to bypass The query planner and going straigt to storage layer, it didn’t result in much faster insertion.
pg-copy-streams came for rescue as it eliminates parsing, planning, and optimization overhead.
Also, COPY uses a single network connection with streaming data, whereas at INSERT each batch requires multiple network calls (BEGIN, INSERT, COMMIT)
Insert 1M records with COPY command
The COPY command is faster than the parameterised query.
30,942 records/second with COPY command (32,32 seconds in total) and 20,820 records/second with batch INSERT (48,06 seconds in total). COPY is 1.48x faster than batch INSERT.
Optimizations in MongoDB
TL;TR: Mongo offers insane performance for insertions if you are willing to go in into some trade-offs. 8.8 seconds for 1M records. This is 3,67x faster than Postgres.
What has been done exactly:
- Writeconcern was set to 0 which means that the database will not wait for the data to be written to the disk.
- Journaling was disabled.
- Indexes on the collection were dropped and created only after the data was fully inserted.
- Unordered inserts were used, so the order of the documents was not guaranteed.
- The min pool size was set to 10 and the max pool size was set to 50.
All in all, most of the optimizations were not making a big difference. The writeconcern and journaling are the two settings that make most of the performance boost. But why?
Writeconcern is a setting that controls the level of write acknowledgement from the server. This required a lot of async operations and a lot of network calls which add up to a considerable overhead. With writeconcern disabled the command is fired and Mongo hopes for the best without knowing that it was written successfully. Journaling is a feature that allows the database to recover from a crash by replaying the journal.
So in the end it’s a trade-off between speed and safety.
Insert 1M records in tuned Mongo
It got wild. I disabled all the safety guarantees and the database was able to insert 1M records in 8.8 seconds. This is 4.2x faster than the default settings.
The average time per record is 0.0088ms and the records per second are 113,636.
MongoDB’s Advantage: Write concern optimization (w: 0, j: false) provides massive performance gains, a 4.2x improvement when durability guarantees are removed PostgreSQL’s Advantage: COPY command is more efficient than MongoDB’s insertMany. The Speed vs Safety Trade-off: MongoDB’s 8.8 seconds: Fire-and-forget writes (data could be lost) PostgreSQL’s 34 seconds: Still has some safety guarantees with UNLOGGED tables.
insertion summary:
While I got inspired by the performance of Mongo and tried to disable all the safety guarantees in postgres too, it didn’t result in any performance boost in postgres. I disabled the wal logging, the autovacuum, dropped the indexes before the insertion, disabled fsync, disabled full page writes, increased the size of shared buffers, etc… This all brought me significant. At some point I even got a worse performance than the inital postgres setup. I’m guessing Postgres just prefers to play it safe.
Insert 1M records in Postgres and Mongo
Here it is: Mongo won the speed game in my experiment. Well done! Yet… running a database without safety measures in production environment is not something which anyone would consider.
READ operations
The second section for this post is about the speed measurements for the read operations. In Mongo and in Postgres I’ve covered the same SELECT cases. There were 19 cases all together with 1M records in the table.
The journey had three distinct phases:
- Phase 1: Untuned - Raw performance with default configurations
- Phase 2: Slightly tuned - Basic optimizations applied
- Phase 3: Properly tuned - Strategic indexing and configuration
The read performance journey
Phase 1: untuned world
Starting with completely default configurations, both databases showed their unoptimized performance. Postgres’ primary key lookups were lightning fast at 0.777ms, while Mongo managed 4.283ms - nearly 5.5x slower for the most basic operation.
Email exact match: Postgres’ early victory
For email lookups, Postgres dominated with 0.622ms compared to Mongo’s 1.260ms. This is a hint on the efficiency of the query planner in Postgres.
Name search
But then: name exact matches without proper indexing: Postgres took 108ms while Mongo managed 42.771ms.
The slowest queries
The most expensive operations revealed fundamental differences. Postgres’ complex OR query took a painful 4.517 seconds, while MongoDB managed the same in 16.244 seconds - nearly 4x slower for complex conditions.
We’re speking the compexity of:
SELECT * FROM users WHERE email LIKE $1 OR email LIKE $2
db.users.find({$or: [{email: {$regex: \"@gmail.com$\"}}, {email: {$regex: \"@yahoo.com$\"}}]})
Pattern matching pain points
Email domain searches showed Postgres at 2.210 seconds vs Mongo’s 7.644 seconds. Untuned Postgres’ LIKE operations significantly outperformed Mongo’s regex matching.
JSON queries: Mongo’s supposed strength
Surprisingly, even for JSON operations, Postgres’ just kept winning. Nested field queries: Postgres 2.023 seconds, Mongo 6.408 seconds.
The executed scripts are:
SELECT * FROM users WHERE user_data->'preferences'->>'theme' = $1
db.users.find({\"user_data.preferences.theme\": \"dark\"}
This was mad to see. This is the database eqivalent to the olimpic victory of the Turkish shooter Yusuf Dikeç.
JSON query averages
For JSON operations where Mongo should excel:
- PostgreSQL JSONB: 1.131s average
- MongoDB Documents: 1.986s average
Postgres was 1.75x faster at handling JSON data. WHAT?!
Complex queries: Postgres just can’t lose
Complex multi-condition queries showed Postgres’ query optimizer at work. Complex queries are conditions where a nested field value is searched for, in concatination
- Postgres: 1.598s average
- Mongo: 5.527s average
A massive 3.5x performance advantage for complex operations.
phase 2: light tuning
After the initial runs, I applied basic optimizations to both databases. Not very thought trough operations, but defining a number of indexes, adding GIN indexes on the JSONB columns, adding partial indexes for common filter conditions, introducing trigram search for text searches… For the sake of getting to a point I will jump straight to the optimized metrics.
phase 3: strategic indexing
The final phase involved proper indexing strategies tailored to each query type. A significant number of indexes were added. This will be visible in the end of the post that sometimes it has messed up the query planner and it was overwhelmed a bit which resulted in some cases in worse performance. Not often though.
Email exact match
With proper indexing not much has changed. Postgres even got worse. Maybe overoptimized?
The name search evolution
The most dramatic transformation: Postgres’ name exact matches went from an embarrassing 108ms to a blazing 0.680ms - a 159x improvement! In Mongo I must have too many e-mail involved indexes by this point becasue it was better without optimizations.
Pattern matching
Postgres’ optimized pattern matching averaged 1.099 seconds compared to Mongo’s 2.744 seconds.
JSON query dominance
Even for document-style queries, Postgres’ JSONB with GIN indexes averaged 1.174 seconds vs MongoDB’s 1.810 seconds. The “use MongoDB for documents” rule was being challenged.
the optimization journey
How the query times have changed over the optimization phases.
Primary key evolution
Primary key lookups remained consistently fast across all tuning phases. PostgreSQL stayed sub-millisecond throughout, while MongoDB improved from 4.283ms to 2.831ms with better configuration tuning.
The name search transformation
PostgreSQL went from a disastrous 108.079ms to a blazing fast 0.680ms with proper B-tree indexing.
Mongo’s rollercoaster journey
MongoDB showed interesting behavior - starting strong at 42.771ms, improving to 0.983ms and going sub-millisecond with compound indexes, but then regressing to 146.783ms in the final highly-tuned phase due to index selection conflicts I guess.
the final comparison
The optimized reality
After proper tuning and indexing, Postgres dominated across almost every category:
- Primary Key: 0.797ms vs 2.831ms (3.5x faster)
- Exact Match: 0.782ms vs 73.97ms (94x faster)
- Pattern Match: 1.099s vs 2.744s (2.5x faster)
- JSON Queries: 1.174s vs 1.810s (1.5x faster)
The index effect
The most dramatic improvements came from proper indexing strategy. PostgreSQL’s B-tree and GIN indexes, combined with its sophisticated query planner, created performance gains that MongoDB’s indexing couldn’t match.
Pattern match dominance
PostgreSQL’s pattern matching efficiency is overwhelming. The search on trigrams results in an adventage of 2-3x over the regex search in Mongo.
JSON performance surprise
The biggest surprise: PostgreSQL’s JSONB performance matched or exceeded MongoDB’s document queries. GIN indexes on JSONB columns provided the speed boost that challenged MongoDB’s core value proposition.
Throughput analysis
Records processed per second:
- Postgres JSON: 145,605 records/sec vs Mongo: 40,887 records/sec (3.6x faster)
- Postgres Pattern: 174,722 records/sec vs Mongo: 2,981 records/sec (58x faster)
These aren’t just incremental improvements - they’re architectural advantages.
takeaways
1. Indexing strategy matters a lot
The most dramatic performance improvements came not from a particular database, but from implementing proper indexing strategies. A 159x improvement in PostgreSQL’s name searches is powerful indeed.
2. Postgres’ query optimizer is sophisticated
Even with similar indexing strategies, PostgreSQL consistently outperformed Mongo. The query optimizer’s ability to choose optimal execution paths even (or maybe especially) with complex queries is impressive.
3. JSONB vs Documents: Postgres wins. Obviously. Duh.
What I was silently hoping for from the beginning: PostgreSQL’s JSONB performance beats Mongo. When for document-style queries Mongo should excel, PostgreSQL with GIN indexes and trigram search performed in my case almost always better.
4. Mongo’s strengths in document queries are worse than expected
Mongo performed well in specific scenarios (some unindexed operations, very simple document retrievals), but PostgreSQL’s performance across diverse query types is just insane.
the verdict
After three phases of optimization and hundreds of benchmark runs, PostgreSQL is the clear winner for read operations. Surely take it with a grain of salt, I had only one data table which is not very production system-like setup. But still… Postgres outperformed Mongo in almost every single case. This means to me that Postgres not only has the relational database adventages but also is a better fit for unstructured data than Mongo. The GIN index and the trigram based search on JSONB columns is a game changer.
complete performance matrix
Here’s the comprehensive view of all benchmark results across all optimization phases. This heatmap shows every single query from all 6 benchmark runs, giving you the complete picture of how each database performed throughout the optimization journey.
Complete Performance Matrix: All Phases Comparison
Performance times in milliseconds or seconds (always displayed accordingly) Green = faster, Red = slower
| Query Operation | Postgres Untuned | Postgres Tuned | Postgres Optimized | Mongo Untuned | Mongo Tuned | Mongo Optimized |
|---|